

Five Minutes
The following previously appeared on KT’s “Clear Thinking” blog.
The website “Scripped” was a screenwriting service, featuring cloud-based writing tools, online storage, and a community to read and critique screenplays-in-process. “Was” is the key word in that sentence. In Spring 2015, registered users logged onto a blank page featuring the startling message that their browser “has detected that the server is redirecting the request for this address in a way that will never complete.”
No April Fool’s joke or trick-or-treat: Shortly thereafter, a message on the homepage indicated that, following a recent change in ownership of the website, the normally scheduled backup process failed – and in the process, wiped clean all previous backups. The previous owners had destroyed their backups, so all that remained of the entire community’s shared database of work was a server image ghosted in 2010.
According to the page (since removed), if writers did not maintain a backup copy of their work, “[Scripped’s webmasters] regret to inform [them] that it no longer exists.” One would have to imagine that most users kept local backups of their work and would not rely entirely on cloud storage for their screenplays; nevertheless, the loss of their creative output must be devastating. (One friend, a talented television writer, lost years’ worth of material in a similar event in 2011; to my knowledge, he has not written since.)
Any time we give up control of our data, or outsource any of our intellectual property, we are putting ourselves and our livelihoods at risk. When I was with Kepner-Tregoe, we frequently encouraged our clients to use a tool called “Potential Problem Analysis” to reduce such threats. In six steps, clients can build action plans that both reduce the chance of a catastrophic event and quickly identify when it becomes time to deploy (a defined) “Plan B.” Here’s how to do it:
The analysis begins with specifically stating the action needing protection. Being specific is important: “Running a Web-Based Service” is broad and can make it difficult to pinpoint a clear list of risks; “Running a Full Backup for the First Time on New Servers” is better to stimulate the type of creative thinking that will yield results.
Next, gather experts (and skeptics) to brainstorm and “Identify Potential Problems” by asking, “When we do this, what can go wrong?” Again, specificity is key. Avoid being tempted to chase a too-large, vague issue – something like, “Backup fails”. That is certainly a concern, but what are the different modes of failure? Are they all equally likely? Equally disastrous? Will they be responded to identically? If the answer to any of those questions is “No”, the potential problem should be clarified further.
In general, listing “what can go wrong” does not require a lot of effort: Having the time or resources to wrestle everything on that list does. Many organizations have their own FMEA-style matrices for prioritizing risks. An alternative is to identify two different dimensions – the probability of failure, and separately its impact – to provide focus on the most critical risks.
From there, it is only natural to want to jump into action; without understanding what might drive the failure, we run the risk of hedging against the wrong issue. Pause and identify the “Likely Causes” of the high-priority potential problems. If you can eliminate a cause, or at least reduce its likelihood, you will have taken a big step in making sure 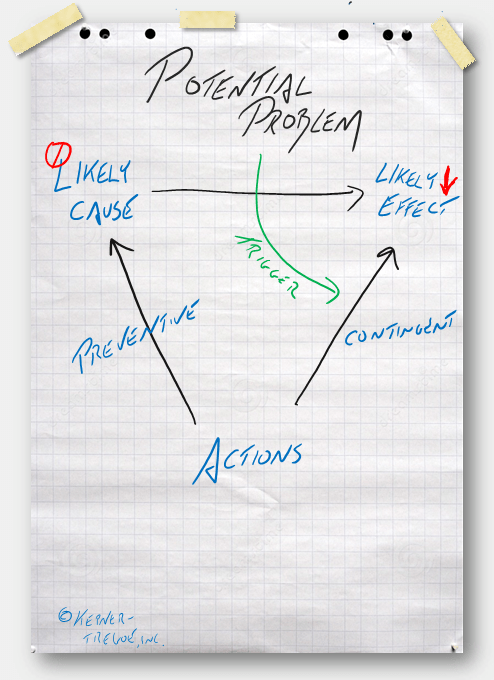 the potential problem does not occur. At the risk of being redundant, the more specific the likely cause, the better the chance of preventing it – “Hardware failure” is open to interpretation; “SSE will not write to IO stream” is something that is manageable. By understanding the root cause, you are taking a more direct, focused attack at the potential problem.
the potential problem does not occur. At the risk of being redundant, the more specific the likely cause, the better the chance of preventing it – “Hardware failure” is open to interpretation; “SSE will not write to IO stream” is something that is manageable. By understanding the root cause, you are taking a more direct, focused attack at the potential problem.
Only then is it appropriate to take action – “Preventive Action”, which is exactly what the name implies. The intent is to prevent the likely cause from happening, in turn protecting the plan. Preventive actions can either attack the likely cause directly, or simply block the cause from creating the potential problem. (For example, it may be impossible to prevent a grid failure, but preventive actions such as installing uninterruptible power supplies can prevent that failure from shutting down equipment).
Many organizations, tired of fire-fighting, stop here. After engineering a perfect solution, and installing countless measures to keep problems at bay, it seems inconceivable that bad things may indeed happen. The last problem review meeting I attended featured engineers from five different disciplines stating, with certainty, that the problem “could not have happened” because of specific design actions they had taken. The fact that we were in a problem review meeting is proof enough that it did happen.
Savvy teams know not to fall victim to this combination of hubris and lack of imagination.
The penultimate step of a good PPA begins by envisioning that the problem has occurred, and it has become time to minimize its effect– setting “Contingent Actions” is what’s needed. The challenge is not to worry about why the problem has happened, but to ask “What will we do when it happens?” Frequently, teams find an answer no deeper than “undo” (CABs always want to know the “back-out plan”); sometimes that is not possible, and other times the smarter play is to steer into the metaphorical skid to escape. The irony here, is backup solutions are a contingent action – invoked when the primary data is either destroyed or deleted.
(It is certainly a Binney Rule, if not yet elevated to a Binney Law: You will always, eventually, create contingent actions; it is better to do so in a conference room, leisurely sipping coffee in front of a white board, then it is when everything has hit the fan, colleagues are panicking, equipment is melting, and contractors are on the clock).
Actions without accountability do no one any good. Setting clear Triggers provides unambiguous notification that a potential problem has indeed occurred, and indicates both the contingent action to be taken, and who should take it.
Potential Problem Analysis Overview:
- Write a clear, specific Action Statement;
- List – then prioritize – Potential Problems of executing that Action;
- Identify Likely Causes of the high-priority potential problems;
- Develop (and assign) Preventive Actions that will eliminate the likely cause;
- Plan Contingent Actions that will mitigate the effect of the potential problem, should it happen; and
- Set Triggers to indicate when the contingent action should be invoked.
Had the new owners of Scripped realized “what could go wrong” with their backup, with the understanding that they did not actually own previous backups, they likely would have taken preventive actions to avoid the debacle. Failing that, if they had identified one or two clear contingent actions, they could have saved critical data before it was too late. Rather, they have become one of too many cautionary tales.
